Explorando los votos — Primera parte: dominando tidyverse
 Congreso Nacional por Pablo Gonzalez en Flickr
Congreso Nacional por Pablo Gonzalez en Flickr
El objetivo de esta entrada y la siguiente es contar una aplicación de mi tesis de licenciatura para la cual usé modelos gráficos no dirigidos para modelar los períodos de votación de las Cámaras del Congreso de la Nación Argentina al estilo de [1].
La idea en particular de esta primera parte es contar cómo manipular los datos en crudo que descargué de acá [2] hasta formar una tabla ordenada que contenga toda la información necesaria. Me interesa revisitar este problema para aprender los paquetes de tidyverse porque me gustaría dejar de ser hipsteR (me sentí muy identificada con el concepto) e incorporar las nuevas herramientas de R. tidyverse es un ecosistema de paquetes orientado al análisis de datos, abarca desde la lectura hasta la comunicación de los resultados. Voy a intentar usar funciones de este entorno siempre que pueda. Como introducción, R4DS [3] es el libro por default y está muy bueno. De hecho, acá está en proceso la traducción al español.
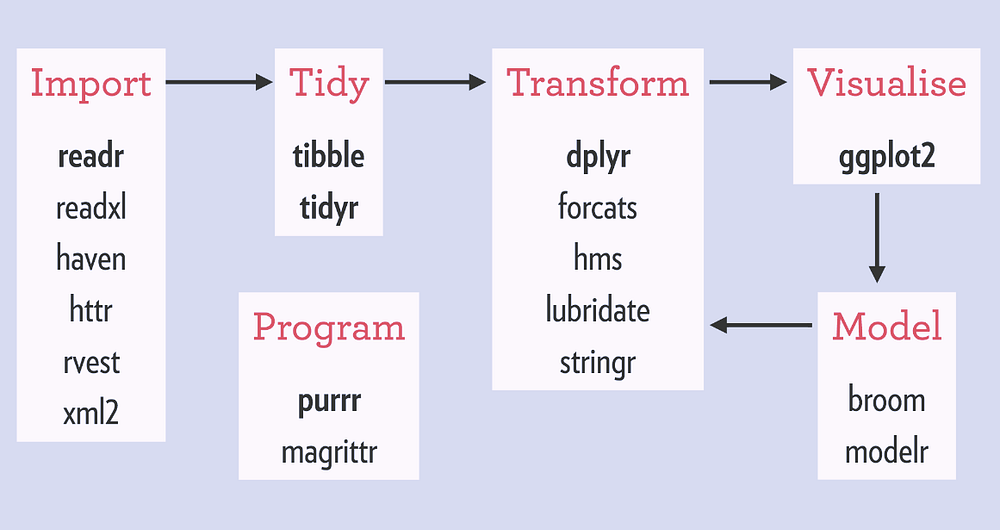 Diagrama de los paquetes de tidyverse by Rstudio
Diagrama de los paquetes de tidyverse by Rstudio
Voy a empezar describiendo los datos crudos que fueron traducidos por decadavotada de pdf a csv :) (Nota: cuando hicimos el análisis no existía pero ahora hay datos más amigables en la página de diputados). Muestro el ejemplo para la cámara de diputados pero el proceso es análogo para los senadores. Usamos los siguientes tablas para generar una única tabla ordenada:
- Una, llamada asuntos, en el cual están todos los asuntos tratados en el período correspondiente. Las variables más importantes para el análisis posterior son: asuntoId (número identificador del asunto) y fecha.
- Otra, llamada diputados, en donde tenemos diputadoId (número identificador del diputado), nombre, el bloque político y la provincia representada.
- Y otra, llamada votaciones, en la cual se especifica para cada diputado como votó en cada una de las votaciones. Las variables son asuntoId, diputadoId, bloqueId, voto (0 = Afirmativo, 1 = Negativo, 2 = Abstención, 3 = Ausente).
 Tablero de una sesión de diputados
Tablero de una sesión de diputados
Como detalle, consideraremos a las abstenciones y ausencias como votos negativos por lo que este dataset tendrá solo dos valores posibles 1=positivo y 0=(negativo, abstención o ausencia). Además, voy a filtrar los diputados que votaron negativamente y/o faltaron demasiado (0s) y también a los que votaron casi en su totalidad positivamente. Esto es debido a que el modelo utilizado en la segunda parte no soporta la falta de variabilidad tan extrema en las variables.
Empezamos por cargar los datos con readr (tip by Jenny Bryan: usar el paquete here que sirve para dejar de tener que hardcodear paths)
asuntos <- read_csv(here::here("datos", "asuntos-diputados.csv"))
diputados <- read_csv(here::here("datos", "diputados.csv"))
votos <- read_csv(here::here("datos", "votaciones-diputados.csv"))
bloques_color <- read_csv(here::here("datos", "bloques-diputados.csv"))y luego seleccionamos los asuntos correspondientes a un período legislativo determinado, en particular para este analisis será el período que va desde 10/12/2013 hasta 9/12/2015, acá el código:
asuntosselec <- asuntos %>%
mutate(fecha = as.Date(fecha, "%m/%d/%Y"))%>%
filter(fecha>ymd("2013-12-10"), fecha<ymd("2015-12-9"))%>%
select(asuntoId)Acá estamos usando implícitamente dplyr (mutate, filter, select) y magritr (%>%).
Nota: como algunas fechas estaban en formato incorrecto fue más fácil usar as.Date que lubridate porque lidiaba mejor con esta inconsistencia.
Ahora seguimos limpiando: borramos las filas repetidas; seleccionamos sólo los asuntos del período que nos interesa; guardamos un vector con la pertenencia de cada diputado a su bloque político que será asociado a un color; nos deshacemos de la variable bloqueId y usamos spread para** **convertir los valores de la variable diputados en las variables de nuestro nuevo dataset pre_dataset:
votosselec <- votos %>%
distinct(asuntoId, diputadoId, bloqueId, voto) %>%
filter(
asuntoId %in% asuntosselec$asuntoId,
bloqueId %in% c(66, 67, 64, 109, 136, 179, 17, 18, 19, 172, 78),
!(diputadoId %in% 1:10)
)
bloques <- votosselec %>%
select(diputadoId, bloqueId) %>%
group_by(diputadoId) %>%
top_n(1, bloqueId) %>%
distinct(diputadoId, bloqueId)
pre_dataset <- votosselec %>%
distinct(asuntoId, diputadoId, bloqueId, voto) %>%
select(-bloqueId) %>%
spread(key = diputadoId, value = voto) %>%
select(-asuntoId)Nos falta cambiar los labels y eliminar los diputados excepcionales:
# cambio labels
dataset <- pre_dataset
dataset[votosselec==1 | votosselec==2 | votosselec==3] <- 0
dataset[votosselec==0] <- 1
# Elimino los diputados que renunciaron, que faltaron mucho o sin varianza en el voto
dataset <- dataset %>%
select_if(~all(!is.na(.))) %>%
select_if(~sum(.)<nrow(dataset)-8) %>%
select_if(~sum(.)>8)Perfecto, ya tenemos un dataset en el cual cada fila representa a un asunto y cada variable/columna representa a un diputado. El valor en la tabla representa si para ese asunto en particular el diputado estuvo a favor (1) o en contra (0).
 View(dataset) en RStudio
View(dataset) en RStudio
Por último nos guardamos una tabla con los nombres de los diputados correspondientes a los Ids:
map_dipu_id <-diputados %>%
filter(diputadoID %in% as.integer(colnames(dataset)[-1])) %>%
select(diputadoID, nombre)En la segunda parte voy a explicar el modelo utilizado y cómo aplicarlo con el paquete IsingFit en una sola línea. También voy a mostrar cómo se hace para obtener un grafo más lindo con ggraph.
Referencias:
[1]* Onureena Banerjee, Laurent El Ghaoui, and Alexandre d’Aspremont. 2008. Model Selection Through Sparse Maximum Likelihood Estimation for Multivariate Gaussian or Binary Data. J. Mach. Learn. Res.* 9 (June 2008), 485–516.
[2] [decadavotada.com.ar](http://decadavotada.com.ar/)
[3]* Garrett Grolemund and Hadley Wickham. 2017. *R for Data Science.
Violeta Roizman
I’m a PhD student in ML. My thesis is focused on unsupervised learning techniques. I like Python and R :)